

CONTENT
こんにちは、大阪エンジニアのYです。
今回はLinux環境下でS3へ接続しファイルを転送する方法を紹介したいと思います。まずは知らない人のためにS3とは・・・というところから説明しておきますね。
S3…「Amazon Simple Storage Service」の略称。
Amazon Web Services (AWS) で利用できる容量無制限のストレージサービス。
AWSが提供するファイル置き場と言い換えると分かりやすいかもしれませんね。
因みにWindowsから利用する場合は、S3専用のツール「S3 Browser」や
FTP転送等でも使用できる「WinSCP」等をインストールしたうえで
接続情報を設定するとGUIベースで操作することが可能です。
ただ、やはりアプリケーションが稼働する環境がLinuxというケースも多くバッチ等にファイル転送を組み込む場合はコマンド操作で処理が実行できることが必須となります。
Linux・・・コマンド・・・と拒否反応を出す人も多いと思いますが
そんなに難しくないので是非チャレンジしてみましょう!
【STEP1】「AWS CLI」をインストールする
特殊な環境で無い限りは以下コマンドで一発です。
# yum install awscli
インストールが完了したら以下のコマンドで正常にインストールが完了しているか
確認しておきましょう。
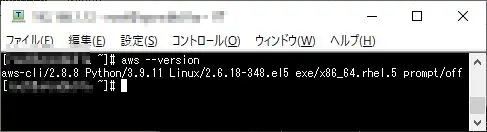
# aws --version
私の手元の環境で上記コマンドを実行した結果は以下となります。
こんな感じで表示されていればインストール完了です。
これでS3に対してコマンド操作によって接続、ファイル転送する前準備ができました。
【STEP2】接続情報を設定する
以下のコマンドを実行して設定情報を入力します。
# aws configure
上記コマンドを実行すると対話方式で以下内容の入力を順に促されるので
接続するS3の環境に沿った内容を入力します。
# AWS Access Key ID [None]:
# AWS Secret Access Key [None]:
# Default region name [None]:
# Default output format [None]:
この設定が完了するとS3への接続準備が完了です。
【STEP3】正しく接続できているか確認する
以下のコマンドを実行して接続先のバケットの一覧を表示します。
バケットはディレクトリのようなイメージを持って貰えると分かりやすいかと思います。
# aws s3 ls
上記コマンドでエラーになることなくバケットの一覧が表示されれば接続成功です。
ここまで設定ができれば、あとはコマンドにて参照するバケットを指定したり、ローカルのファイルをアップロードしたり、バケットのファイルをダウンロードしたり諸々の操作が可能となります。
細かいコマンドの紹介は今回は割愛しますのでリファレンス等で確認して頂ければと思います。
どうですか?たった3ステップで接続までできましたね。
分かってしまえば意外とハードルは低いと感じた人も多いかと思います。
ひと昔前だと外部とファイルをやり取りする際にFTP用のサーバを構築して、
そこで相互にやり取りすることが多かったですが、最近S3を使用するケースが増えてきました。
知識として知っておいて損は無いと思うので是非ご活用下さい!